

医療ビッグデータが社会を変える
関西健康・医療創生会議セミナーより
京都大学大学院医学研究科
中山健夫教授
みなさん、ビッグデータという言葉をいつごろから聞かれているでしょうか。自然科学系のトップジャーナル「ネイチャー」では、2008年にビッグデータの特集がありました。その後、題名にビッグデータが含まれる論文が急増しています。
ただ、ビッグデータという言葉のきちんとした定義というと、意外によく分からない。ある重鎮の先生は、「(表計算ソフトの)EXCELで開けないのがビッグデータだ」とおっしゃっていて、定義とはいえなさそうですけども、すごく一般向けに分かりやすく解説しています。

◆これまで見えなかったことがビッグデータを通して見えてくる
いろんな解説などを読んでみますと、4つの「V」というのが出てきます。Volume(容量)、Velocity(迅速性)、Variety(多様性)、veracity(正確性)です。この4つのVを持ったビッグデータを賢く慎重に活用することで、今まで見えなかったことが見えてくるのです。
ただ、特徴は長所になりますが短所にもなりますから、使い方を間違えたら大変です。「データ」と「情報」の違いはあまり意識されていませんが、データは客観的に観測されたもの、情報はそれに解釈や意味合いが加わります。ビッグデータを良いことばかりだと思っている人も多いのですが、間違った解釈を加えると間違った情報になってしまうのです。
健康寿命を伸ばすことが医療の大きなテーマです。元気で長生きという社会をつくるには治療が大事ですが予防も大事。例えば、脳血管疾患の背景には高血圧、糖尿病、喫煙、過剰飲酒などがあるということが分かっています。みなさんは当たり前だと思うかもしれませんが、これらは黙っていて自動的に分かるものではありません。これまでに、きちんとデータが集められ、きちんとした方法論で専門家が分析した結果、分かったことなのです。
脳卒中の危険因子、どんな人が脳卒中になりやすいかといえば、血圧の高い人ですね。これは一般常識のように思うかもしれませんが、1995年の医学系ジャーナル「ランセット」には世界中の45万人を追跡調査したら1万3千人に脳卒中が発生しており、血圧やコレステロールと脳卒中の関係を調べたという話が載っています。また、100万人の追跡調査を行った結果、血圧やコレステロールと脳卒中の関係が極めてクリアに分かったという研究もありました。こういった作業を行わなければ、高血圧が脳卒中のリスクを高めるということは言えないわけです。経験論も大事ですが、データが非常に重要です。
こうした研究を「疫学」といい、この20年ぐらいで日本でもさかんになってきました。滋賀医大が中心になって18万人の追跡調査を行った研究がありますが、例えば年齢40歳で血圧140の男性がその後で脳卒中になるリスクが分かる。同じ血圧140でも年齢ごとにリスクが異なる。それぞれの年齢、それぞれの血圧で、どれだけ死亡率が違うかも分かる。
こういったことを丁寧に分析していくと、どんなことが可能になるか。例えば、生活習慣や検診結果について20項目ぐらいを聞けば、みなさんの寿命が分かります。さらに、分かって終わりではなく、生活習慣などを変えることでリスクを減らすことができるのです。
◆「今は健康だけど、将来どうなるか?」という問いに答える
さて、ビッグデータがあればOKかというと、それは違います。データと情報は別のものですから、間違って使うとおかしな方向へ行ってしまいます。そこで大事なのが、疫学という研究方法です。
日本の医学において、疫学は低く見られてきた学問です。医学研究というと、臨床で患者を診ている医師であっても、研究になると病棟を離れて頭を切り替え、動物実験を行っていたのです。生命科学とそしてはそれで正しいのですが、私たちは人間のことを知りたい。しかし、人間のしくみは複雑で手がつけにくいから、まず動物実験でさまざまなことを明らかにして、医学は進歩してきました。ただ、これからは人間において何が正しいのかを探していかなければなりません。まさに医療ビッグデータが問われる時代です。
疫学とは、人間において病気や健康に関する因果関係を解明し、予防や治療に役立てる科学、すなわちデータから人間を守る情報をつくり出す研究です。
私たち京都大学大学院医学研究科社会健康医学系専攻は、2000年に発足した国内初となるパブリックヘルス領域の専門職大学院です。臨床なら例えば呼吸器内科とか消化器外科、基礎であれば解剖学や病理学といったイメージですが、こちらは医療統計学、医療疫学、ゲノム疫学、医療経済学などの分野があり、疫学とつくものだけで5つとなります。
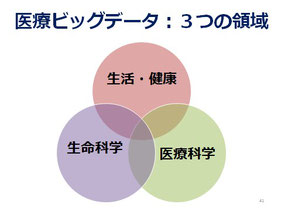
医療ビッグデータには同じ医学でも大きく分けて2つの領域があります。ひとつが生命科学で、ゲノムの遺伝子のデータや創薬のために化合物データなどを扱っている。もうひとつは医療科学で、検診やレセプト、死亡情報などを扱うことが多い。もちろん決して対立しているわけではありませんが、それぞれ重きを置いている部分が少し異なります。
ゲノムや遺伝子の研究は、この50年で非常に進歩しました。2003年には人間のゲノムがすべて解読されました。その次には、それぞれの遺伝子が実際の人間にとってどんな意味があるのか、どんな病気に関係しているのか、という突き合わせを行う必要があります。最近、商業ベースの遺伝子検査で、何万円かを支払うと「糖尿病になりやすい」とか「あなたは芸術家タイプ」などと分かってしまうという話もありますが、それはありえません。
これは、たくさんの人間のゲノムを読んで、例えばタイプAを持っている人は10人に1人が糖尿病になった、タイプBを持っている人は3人に1人だった、そうするとタイプBはAに比べて3倍のリスクがある、といったことを、きちんとした疫学研究で突き合わせをしなければなりません。いきなりゲノムを読んで糖尿病や芸術家が出てくるわけがないのです。
大規模ゲノム疫学研究でひとつの嚆矢となったのは、50万人のデータを集めた「英国バイオバンク」です。知りたいのは、「今は健康だけど、将来どうなるか」ということ。それは、コホート研究、つまり追跡調査をしないと分からない。そこで、ひとりひとりの血液、ゲノム情報、生活習慣、環境といったデータを集め、その人がどういう病気になるかを追跡する。「将来の世代のため研究に参加してほしい」といって50万人を集めたそうです。
これと同様の取り組みは日本でも始まっており、名古屋大学や東北大学などゲノム疫学研究は10万人規模。私たち京大医学研究科では、滋賀県長浜市と協定を結んで、1万人規模の特徴あるコホート研究をやっています。「ながはま0次予防コホート事業」といいまして、30歳から74歳までに方に参加してもらっています。条例を制定して、市民の信頼を得ながら安全にゲノム研究を行っています。
◆毎年20億件のレセプトを蓄積
もう一方、医療科学におけるビッグデータですが、2003年に急性期病院へ診断群分類が導入され、これは標準化されたデータなので研究にも使えるように整ってきました。それと並行して、2011年から全医療機関にレセプトの電子化が義務付けらました。また、2008年に「高齢者の医療の確保に関する法律」が施行され、レセプトや特定検診などのNDB(ナショナル・データ・ベース)と呼ばれるものが意識されるようになりました。
NDBの潜在的価値というのは、超高齢者を含めた国民皆保険制度においてどのような医療が行われているのか1億人規模の人口を擁する国レベルで解明できる現時点では世界で唯一、そして最大のデータベースだということです。
これは国による大きなデータベースで、生活保護者などを除いた基本的にほぼすべての日本人のデータが入っており、毎年20億件のレセプトが蓄積されていきます。そう聞くと一見すごいものに思えますが、非常に使いにくいデータでもあり、現在が限られた研究者がいろいろ試行錯誤しているという段階です。
ここで重要な点として、薬害の再発防止があります。薬害肝炎の際に出された提言には、「電子レセプト等のデータベースから得られた情報を活用し、薬剤疫学的な評価基盤を整備することが必要」「個人識別子などを用いて、電子カルテ等のデータへのリンクを可能とし、高度な分析への活用を可能にすることの検討も行う」と記されています。こういったことが遅まきながら日本でも進んでいます。
海外では、データベースを応用した 医薬品安全性の研究や副作用への迅速な対応といったことが、非常に進んでいます。イギリスの事例ですが、開業医を中心にした36万人の診療情報データがあり、非常に応用しやすい、使い勝手のいいデータベースとなっています。
ビスホスホネートという骨粗鬆症の薬があります。これを飲んでいる日本とヨーロッパの患者さんのうち何人かが食道がんになったという報告がアメリカで出た。
薬の副作用ではないかという話になり、本当にそうだとすれば非常に深刻な話です。もちろん、これだけではビスホスホネートに食道がんの副作用があるとはいえません。食道がんはこの薬を飲んでいない人にも発生するからです。 ビスホスホネートを飲んでいない人より飲んでいる人のほうに食道がんが多く発生していると分かったら、初めて副作用かもしれないといえる。きちんとしたデータに基づいて、疫学研究、コホート研究を行う必要があるのです。 そこで、年齢や性別などをマッチングさせた、この薬を飲んでいる人と飲んでいない人のデータを調べました。飲んでいる人41826人、飲んでいない人41826人。年齢や飲酒、喫煙、ほかに使っている薬などを一致させます。そうすれば、本当に薬を飲んでいる人に食道がんが多いのか、ようやく検討できるのです。 データがそろっていて、きちんとした方法論があれば、こうして迅速に対応できる。世の中の不安に対して素早く答えることが可能なのです。残念ながら、日本ではまだこういうことはできません。

◆社会的な課題を議論するための土台にほかにもレセプトを活用した研究をいくつか紹介
ある患者さんがひとつの病気で1カ月の間にあちこちの病院に行ってたくさん薬をもらってしまう、重複処方という問題があります。124万人のレセプトを分析した結果、精神科の病気でひとつの医療機関の処方を受けた人が19277人、ふたつの医療機関が551人、みっつの医療機関に行った人もいた。そして、11や12の医療機関で処方を受けた人もいることが分かりました。これは、おかしい。
このように、ビッグデータによって少ない数では分からなかったような稀なことも見えてきます。これをテイル分析といいますが、テイルとはしっぽのことです。ビッグデータによって少ない数だと分からなかった傾向がうっすら見えてくるという利点のほかに、外れ値に問題が潜んでいることもあるのです。木を見ながら森を見る、両方できるということです。
また、私たちが2014年から2016年に行った厚生労働省の戦略研究では、臨床の先生方にも協力してもらい、潜在的不適切処方や高齢者の終末期・緩和ケアといったテーマについて検討しました。
高齢者の不適切処方とは、「高齢者において避けることが望ましい薬剤」の問題です。認知機能を低下させるなど高齢者にとって懸念のある薬について、実際どのくらい高齢者に処方されているのか。
例えば、ベンゾジアゼピン系の薬。これは昔からある良い薬ですが、高齢者が長く使うと認知機能が落ちたりする。また、抗炎症鎮痛剤は関節痛などの痛み止めとして飲みたいというお年寄りが多いが、腎機能を悪化させることもある。もちろん、これらがすべて不適切だというわけではなく、分かっていても必要だから処方するということはあります。しかし、75歳以上の1400万人についてNDBのデータを解析してみると、ちょっと多いのではないかということが分かった。
このように、いままで見えなかったことが、ビッグデータによって明らかになってきます。ただ、見たいものばかりではなく、見たくないものもたくさんあります。そこからどう良い方向へ向けていくか、それが問われているのです。
高齢者の終末緩和医療も重要です。近年、高齢者が亡くなる直前に必要のない医療を受けているのではないかという問題意識が大きくなっています。
例えば、亡くなる1週間前にどんな医療が行われたのか、レセプトで分かります。ICU入室、心肺蘇生術、気管内挿管、人工呼吸などを延命的な治療と定義して、どれくらい行われているかを調べました。終の棲家となりうる療養病床において、約7%で心肺蘇生術が行われています。療養病床で少しずつ衰えて最期を迎える患者さんに、心臓が止まったから心肺蘇生術を行うというのが本当に必要でしょうか。もちろん、心肺蘇生術で回復することもあるので一概には言えません。これらは後から見た結果であって、助かると思って一生懸命やっているケースも少なくないでしょう。ただ、自分がそういった状況になったらどうしてほしいか、考えておく必要があるのではないでしょうか。
このように、医療ビッグデータの解析はこれから日本社会が向き合わなければならない議論の土台にもなります。
◆きちんと情報が管理されていなければ適切な医療が受けられない
次は、さまざまなデータ同士をリンクさせた研究をご紹介しましょう。携帯電話の電磁波が脳腫瘍のリスクを高めるという話を聞いたことがあるでしょうか。いろいろな動物実験が行われていますが、私たちが知りたいのは人間のこと。そのためには、やはり疫学研究が必要です。
これについて、デンマークで行われた大規模な疫学研究があります。生まれたときから決まっている個人識別番号を使って、国民の診療データベースと携帯電話会社の契約記録をリンクさせました。すると、携帯電話を長く使っていた人もそうでない人に比べて脳腫瘍のリスクが高いということはなかったとの結果が出た。これは医学の研究ですが、病院内のデータだけではできません。病気の原因は病院の外にあるのです。こういった研究を可能にしているのは国による共通IDです。
日本のマイナンバーでは医療や介護はデリケートな問題だということで保険や年金と切り離されましたが、私は医療分野でこそ活用すべきだと思っています。
必要で適切な医療を提供するためには、妊娠や出生、ワクチン接種、学校検診、成人検診、がん検診、どんな医療を受けたか、といったデータが共通IDで管理される必要があります。人間の一生をデータにしておくのです。国に管理されるのが嫌だという方もいらっしゃいますが、そうでなければ必要なときに必要なサービスを提供できるインフラになりません。かつて消えた年金問題というのがありましたが、ちゃんと国に自分たちの情報を管理してもらっていないと受けるべき利益を受けられないということもある。人間を守るために共通IDが必要なのです。
これからは、自分のパーソナル・ヘルス・レコードがスマホに入っていて、病院に行って医師にアクセスしてもらえればそれまでの医療情報が分かる、そういう時代になるのではないでしょうか。
【中山健夫教授の経歴】
1987年に東京医科歯科大学を卒業後、同大学難治疾患研究所疫学部門助手、米カルフォルニア大学ロサンゼルス校フェロー、国立がんセンター研究所がん情報研究部室長などを経て、2000年に京都大学大学院医学研究科社会健康医学系専攻助教授。2006年から同教授、2016年からは同専攻長および医学研究科副研究科長。専門は健康情報学。医療の現場に患者の視点を反映させるため病気や医療で患者が感じたことを体系的に研究する「患者体験学」にも取り組む。日本疫学会理事、厚生労働省費用対効果評価専門組織委員、医療ビッグデータコンソーシアム世話人など多数の役職を務める。